
Trabajar con Unicode en JavaScript – Parte 2
En el primer artículo sobre Unicode en JavaScript hicimos una introducción a Unicode, te recomiendo su lectura antes de seguir si no tienes muy claro cómo funciona. Vamos a ver a continuación como funciona JavaScript con Unicode.
JavaScript utiliza UTF-16 como codificación interna de las strings, por lo que podemos usar cualquier símbolo dentro de las strings como se muestra a continuación.
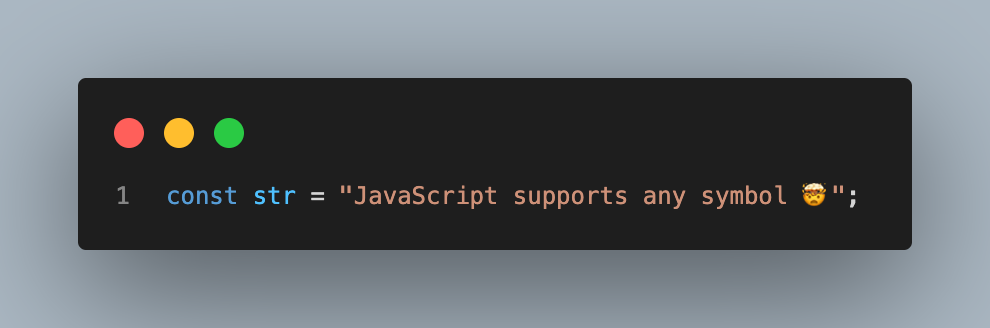
Además también soporta como nombre de variable cualquier símbolo unicode del plano BMP como se puede ver a continuación.
const π = 3.14159;
const ಠ_ಠ = "suspicious...";Aunque nuestro código pueda quedar muy elegante si lo llenamos de símbolos Unicode, puede que nos den problemas con navegadores o sistemas antiguos, o que directamente necesitemos escribir carácteres como el Zero Width Joiner que darían problemas a la hora de trabajar o leer el código.
Usando secuencias escapadas en JavaScript
¿Qué es una secuencia escapada?
Una secuencia escapada es una manera de usar un símbolo unicode sin tener que escribirlo directamente. Seguramente alguna vez hayas visto el típico \r para representar un salto de línea, esto sería un ejemplo de secuencia escapada.
Secuencias de escape unicode
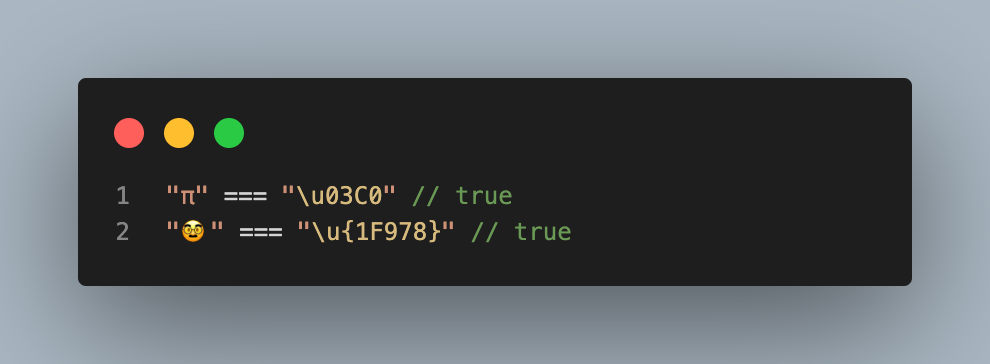
En JavaScript podemos usar las secuencias de escape con \u seguido de 4 dígitos hexadecimales para representar el punto de código Unicode. En vez de poner el símbolo π podemos usar una secuencia escapada como \u03C0.
"π" === "\u03C0" // truePosiblemente te habrás dado cuenta de un problema, y es que con 4 dígitos no podemos representar todos los símbolos unicode, solamente el plano BMP.
¿Qué pasa con el resto de planos?
En ECMAScript 6 tenemos otra notación llamada unicode code point scapes. Esta notación es muy parecida pero los dígitos hexadecimales van dentro de llaves, y podemos usar todos los que necesitemos.
¿Y con ECMAScript 5? Pues bien, para representar los planos astrales con las secuencias escapadas de unicode se utilizan los pares subrogados. Consiste en representar un punto de código con un par de secuencias de escape como podemos ver a continuación.
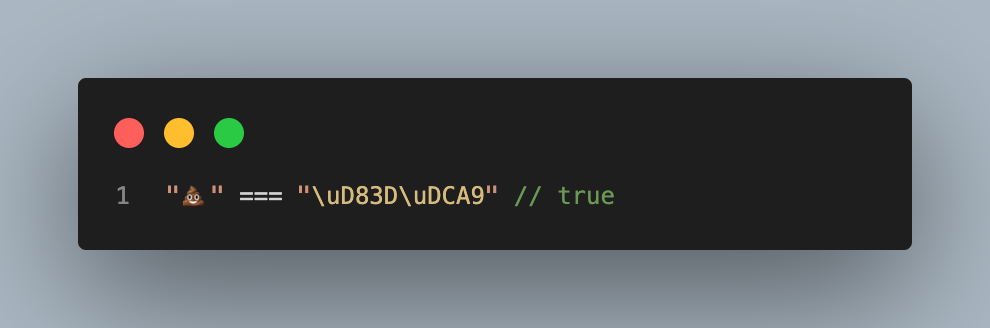
La manera de calcular el par subrogado no es directa, si no que existen fórmulas para convertir un punto de código en par subrogado y viceversa. Hay que tener en cuenta que JavaScript representa los símbolos astrales como pares subrogados internamente, y que cada mitad de par subrogado es un carácter, veremos esto más adelante.
Dolores de cabeza 🤯 que causa Unicode
Vamos a ver algunos ejemplos contraintuitivos que se dan con JavaScript, aunque con lo que hemos aprendido hasta ahora no nos parecerán tan extraños.
Strings con longitudes extrañas
Veamos el siguiente ejemplo de longitudes de strings.

Seguramente pienses que me he inventado los resultados de las longitudes, pero tienes que tener en cuenta tres claves:
- JavaScript internamente utiliza los pares subrogados.
- En Unicode podemos usar carácteres de combinación como el «Combining Tilde» para formar la ñ.
- El emoji de la familia se forma uniendo los emojis de cada miembro (2 carácteres por ser pares subrogados) y necesitamos tres «ZWJ» para unirlos ( 4*2+3 = 11 ).
Sabiendo estas tres cosas todo cobra sentido.
Strings similares pero distintas
Para ver este caso vamos a utilizar otra vez el ejemplo anterior con la palabra mañana:
"mañana" === "mañana" // falseComo hemos visto antes, la letra ñ puede ser un símbolo propio, o formarse como la suma de n + ~. Sería un uso interesante para usar como contraseña, y que no se pueda usar aunque te la lean por encima del hombro.
Invertir strings
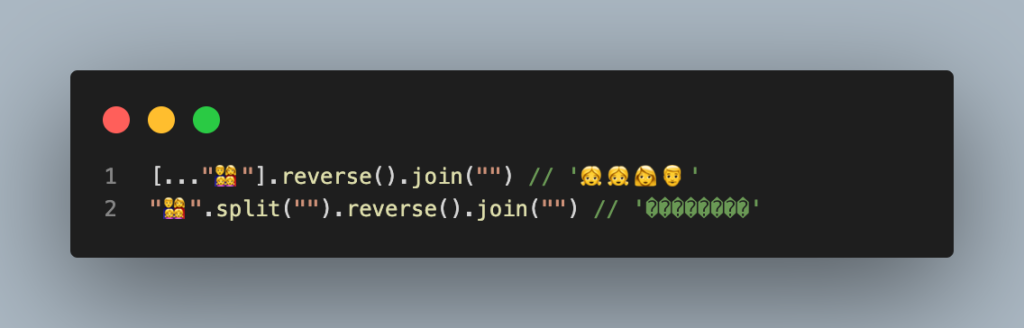
JavaScript no tiene un método para darle la vuelta directamente a una string, pero si que lo tiene para los arrays, por lo que podrías usar un código como el siguiente para dar la vuelta a las cadenas de texto.
const someString = "Some string to be reversed";
someString.split('').reverse().join('');Y funciona muy bien… siempre y cuando no tengas pares subrogados o símbolos de combinación en el texto, ya que con los pares subrogados pasa lo siguiente
const str = "man\u0303ana"
str.split('').reverse().join(''); // anãnamEn el caso de tener pares subrogados, podemos usar la sintáxis spread para convertir una string a array y se respetarán los pares subrogados.
Puedes ver mas problemas de JavaScript con Unicode en este articulo.
Normalize al rescate
En ECMAScript 6 tenemos la función normalize que nos permite normalizar nuestras strings según la normalización Unicode, con las cuatro formas posibles. De esta manera podremos evitar todos los problemas que nos pueden causar los carácteres de combinación de Unicode, ya que podremos dejarlos combinados. Por ejemplo si tenemos n + ~ podremos convertirlos en ñ.
¿Qué podemos hacer con Unicode?
Ahora que ya «dominamos» Unicode y cómo tratarlo con JavaScript podemos ver algunos usos «avanzados» que podemos darle.
Motor de búsqueda básico
Imagina que queremos hacer un buscador de productos. Los productos pueden tener en el nombre carácteres especiales o acentos. Una manera muy sencilla de normalizar el texto y poder mostrar resultados al usuario aunque no introduzca los acentos sería con:
const normalize = (text) =>
text
.normalize("NFD") // Normalizamos por descomposición
.toLowerCase() // Lo pasamos a minúsculas
.replace(/[^\w\s\u{303}\u{327}]/giu, "") // Eliminamos caracteres que no sean letras, números, espacios o \u{303}\u{327}
.normalize("NFC"); // Normalizamos por composiciónEsta función descompone todos los carácteres unicode, de manera que separaría acentos de letras, y tildes de ñ o la cedilla de la ç, luego eliminaría todos los carácteres menos los carácteres de palabras, espacios, la cedilla y la tilde de combinación y luego vuelve a combinarlos.
De esta manera tenemos una búsqueda mejorada con respecto a un simple includes o indexOf.
Jugar con los emojis
Ahora vamos a suponer que estamos montando un webchat y que queremos que los usuarios puedan representarse con un emoji. Podríamos poner toda la lista de secuencias ZWJ o podríamos hacerle distintas preguntas, como si es hombre o mujer, tono de piel, tipo de pelo y color e ir combinando los emojis correspondientes a las respuestas.
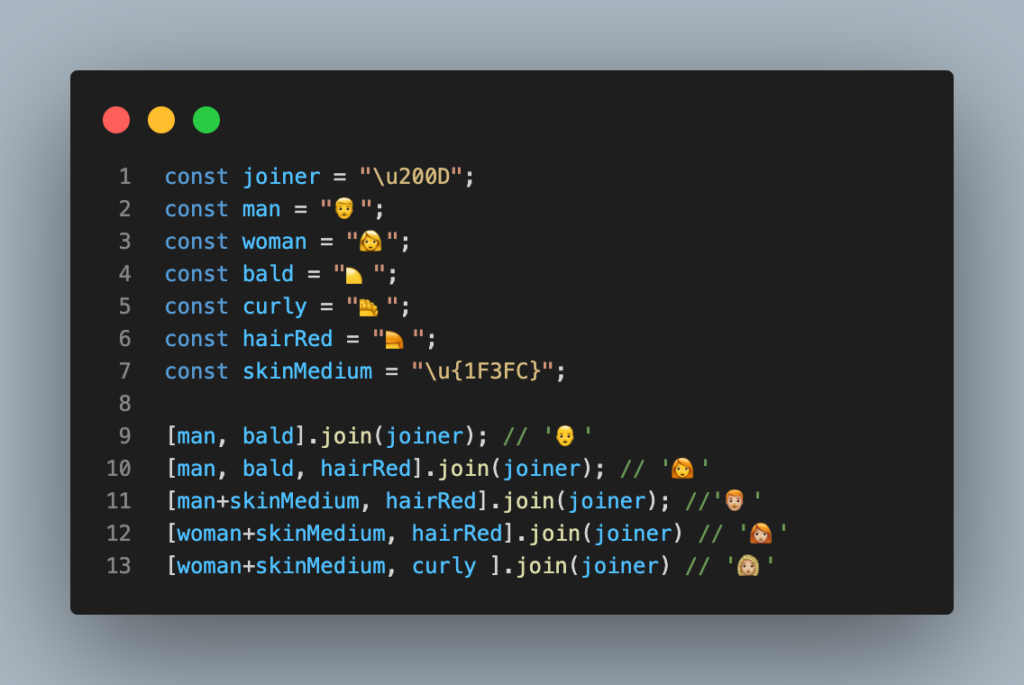
Como puedes ver en el código, ¡el tono de piel no se une con el símbolo ZWJ!
Espero que te hayan resultado útiles e interesantes estos dos artículos sobre JavaScript y Unicode. Tengo que hacer especial mención al blog de Mathias Bynens (@mathias) ya que sus artículos me han ayudado un montón a poder comprender el funcionamiento de Unicode y cómo lo trata JavaScript.